首先我们要装一个字符串处理的包,stringr包,tidyverse包是我们的字符串例子包。
install.packages(tidyverse)
install.packages(stringr)
library(tidyverse)
library(stringr)
字符串基础知识
我们可以使用单引号或双引号创建字符串。建议总是使用",除非你想创建一个包含多个的字符串",那就用'。
string1 <- "A string"
string2 <- 'print"hello world"'
如果你忘记关闭引号,你会看到+,延续字符:
> "A string without a closing quote
+
+
+ STUCK
如果发生这种情况,请按Esc或者CTRL+C键并重试!
要在字符串中包含文字单引号或双引号,可以使用\来进行转义:
string1 <- "\"" # or '"'
string2 <- '\'' # or "'"
这意味着如果你想要包含一个文字反斜杠,你需要再加一个:"\\"。
请注意,字符串的打印表示形式与字符串本身不同,因为打印的表示形式显示了转义符。要查看字符串的原始内容,请使用writeLines():
x <- c("\"", "\\")
x
#> [1] "\"" "\\"
writeLines(x)
#> "
#> \
还有一些其他特殊字符。最常见的是"\n"换行符和"\t"制表符,但我们可以通过以下方式来查看完整列表":?'"'或?"'"。有时也会看到字符串"\u00b5",这是一种编写适用于所有平台的非英文字符的方法:
x <- "\u00b5"
x
#> [1] "µ"
多个字符串通常存储在字符向量中,可以使用c()以下方法创建:
c("one", "two", "three")
#> [1] "one" "two" "three"
字符串长度
我们将使用stringr中的函数。它们有很直观的名字,一切都始于str_。例如,str_length()告诉字符串中的字符个数:
str_length(c("a", "R for data science", NA))
#> [1] 1 18 NA
组合字符串
要组合两个或更多字符串,可使用str_c():
str_c("x", "y")
#> [1] "xy"
str_c("x", "y", "z")
#> [1] "xyz"
使用sep参数来控制它们中间的间隔字符:
str_c("x", "y", sep = ", ")
#> [1] "x, y"
要将字符串向量折叠为单个字符串,请使用collapse:
str_c(c("x", "y", "z"), collapse = ", ")
#> [1] "x, y, z"
如上所示,str_c()是矢量化的,它会自动将较短的矢量再循环到与最长矢量相同的长度:
str_c("prefix-", c("a", "b", "c"), "-suffix")
#> [1] "prefix-a-suffix" "prefix-b-suffix" "prefix-c-suffix"
长度为0的对象将被静默删除。这与if以下内容特别有用:
name <- "Hadley"
time_of_day <- "morning"
birthday <- FALSE
str_c(
"Good ", time_of_day, " ", name,
if (birthday) " and HAPPY BIRTHDAY",
"."
)
#> [1] "Good morning Hadley."
子集字符串
可以使用提取字符串的一部分str_sub()。以及提供子字符串(包含)位置的字符串,在这个函数的后面两位写截取的起始和终止位置:
x <- c("Apple", "Banana", "Pear")
str_sub(x, 1, 3)
#> [1] "App" "Ban" "Pea"
# negative numbers count backwards from end
str_sub(x, -3, -1)
#> [1] "ple" "ana" "ear"
语言环境
str_to_lower()将文字改为小写。你也可以使用str_to_upper()或str_to_title()。但是,更改案例比最初出现时更复杂,因为不同的语言对于更改案例有不同的规则。可以通过指定区域设置来选择要使用的规则集:
str_to_upper(c("i", "ı"))
#> [1] "I" "I"
str_to_upper(c("i", "ı"), locale = "tr")
#> [1] "İ" "I"
语言环境被指定为ISO 639语言代码,它是两个或三个字母的缩写。如果还不知道语言代码,维基百科有一个很好的列表。如果将区域设置留空,它将使用操作系统提供的当前区域设置。
受语言环境影响的另一个重要操作是排序。基本R order()和sort()函数使用当前语言环境对字符串进行排序,我们也可以使用str_sort()并str_order()采用其他locale参数:
x <- c("apple", "eggplant", "banana")
str_sort(x, locale = "en") # English
#> [1] "apple" "banana" "eggplant"
str_sort(x, locale = "haw") # Hawaiian
#> [1] "apple" "eggplant" "banana"
使用正则表达式匹配字符
正则表达是一种非常简洁的语言,允许我们概述字符串中的特殊模式。
要学习正则表达式,我们将使用str_view()和str_view_all()。这些函数采用字符向量和正则表达式,并显示它们如何匹配。我们将从非常简单的正则表达式开始,然后逐渐变得越来越复杂。一旦掌握了模式匹配,我们将学习如何将这些功能应用于各种字符串函数。
基本匹配
最简单的模式匹配:
x <- c("apple", "banana", "pear")
str_view(x, "an")

下一步是.,匹配任何字符(换行符除外):
str_view(x, ".a.")

何那我们如何去匹配真正的.符号呢?
可以用转义字符“\\."
dot <- "\\."
str_view(c("abc", "a.c", "bef"), "a\\.c")

如果\在正则表达式中用作转义字符,那么如何匹配文字\?
那就用四个"\\\\"
x <- "a\\b"
writeLines(x)
#> a\b
str_view(x, "\\\\")
![]()
开头结尾(锚定)
默认情况下,正则表达式将匹配字符串的任何部分。锚定正则表达式以使其与字符串的开头或结尾匹配通常很有用。可以使用:
^匹配字符串的开头。$匹配字符串的结尾。
x <- c("apple", "banana", "pear")
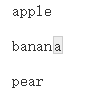
str_view(x, "^a")

str_view(x, "a$")
字符类和替代方案
有许多特殊模式匹配多个字符。你已经看过.,它与换行符之外的任何角色都匹配。还有其他四个有用的工具:
\d:匹配任何数字。\s:匹配任何空格(例如空格,制表符,换行符)。[abc]:匹配a,b或c。[^abc]:匹配除a,b或c之外的任何内容。
请记住,要创建包含\d或的正则表达式\s,需要转义\字符串,因此我们将键入"\\d"或"\\s"。
str_view(c('abc','a1234f'),'a[\\d]*f')

您可以使用|符号选择一个或多个替代模式。例如,abc|d..f将匹配'“abc”'或"deaf"。与数学表达式一样,如果优先级变得令人困惑,请使用括号清楚地表达想要的内容:
str_view(c("grey", "gray"), "gr(e|a)y")

重复
下一步的涉及模式匹配的次数:
?:0或1次+:1次或更多*:0次或更多
x <- "1888 is the longest year in Roman numerals: MDCCCLXXXVIII"
str_view(x, "CC?")
![]()
str_view(x, "CC+")
![]()
还可以精确指定匹配数:
{n}:n次{n,}:n或更多{,m}:最多m{n,m}:在n和m之间
str_view(x, "C{2}")
![]()
str_view(x, "C{2,}")
![]()
检测匹配
要确定字符向量是否与模式匹配,请使用str_detect()。它返回一个与输入长度相同的逻辑向量:
x <- c("apple", "banana", "pear")
str_detect(x, "e")
#> [1] TRUE FALSE TRUE
提取匹配
要提取匹配的实际文本,请使用str_extract()。
length(sentences)
#> [1] 720
head(sentences)
#> [1] "The birch canoe slid on the smooth planks."
#> [2] "Glue the sheet to the dark blue background."
#> [3] "It's easy to tell the depth of a well."
#> [4] "These days a chicken leg is a rare dish."
#> [5] "Rice is often served in round bowls."
#> [6] "The juice of lemons makes fine punch."
我们想找到包含颜色的所有句子。我们首先创建一个颜色名称向量,然后将其转换为单个正则表达式:
colours <- c("red", "orange", "yellow", "green", "blue", "purple")
colour_match <- str_c(colours, collapse = "|")
colour_match
#> [1] "red|orange|yellow|green|blue|purple"
现在我们可以选择包含颜色的句子,然后提取颜色以确定它是哪一个:
has_colour <- str_subset(sentences, colour_match)
matches <- str_extract(has_colour, colour_match)
head(matches)
#> [1] "blue" "blue" "red" "red" "red" "blue"
替换
str_replace()并str_replace_all()允许您用新字符串替换匹配项。最简单的用法是用固定的字符串替换模式:
x <- c("apple", "pear", "banana")
str_replace(x, "[aeiou]", "-")
#> [1] "-pple" "p-ar" "b-nana"
str_replace_all(x, "[aeiou]", "-")
#> [1] "-ppl-" "p--r" "b-n-n-"
str_replace_all()可以让我们通过提供一个向量执行多个替换:
x <- c("1 house", "2 cars", "3 people")
str_replace_all(x, c("1" = "one", "2" = "two", "3" = "three"))
#> [1] "one house" "two cars" "three people"
分割
使用str_split()最多将一个字符串分解成碎片:
x<-"234235fgq35423dvfwrfgw3534fgerg"
str_split(x,'[\\d]+')
[[1]]
[1] "" "fgq" "dvfwrfgw" "fgerg"
转换
使用is.character()可以检验数据类型是否是字符串:
is.character('hello')
[1] TRUE
is.character(1)
[1] FALSE
使用as.numeric()可以将字符串转为数字进行运算:
a<-'123456'
as.numeric(a)+10000
[1] 133456
鹃儿
1楼 - 5 年,5 月 之前
这个字符串的处理总结的很好。