数据都进来了,下一步要做的是查看数据质量怎么样?尤其要关注的两个问题是,有没有缺失值和异常值。
缺失值
这个很好理解,就是数据不见了呗。比如采集了5000行500列数据,其中某几个数据因为采集或者记录原因失败了,就造成了缺失值。缺失值在R语言中一般用NA来代替。(比如读取文件的时候,如果有些行有些列没有数值,就会自动填为NA)。
R使用NA(不可得)代表缺失值、NaN(不是一个数)代表不可能的值、Inf和-Inf代表正无穷和负无穷,函数is.na()、is.nan()、is.infinite()可分别用于识别缺失值、不可能值和无穷值。
再读取了一批文件以后,我们可以用na.fail()来看函数的有没有缺失,is.na()函数来查看缺失值:

缺失值可视化
简而言之就是,想要直观地看看你的数据中缺失值在哪里。最直观的看法就是使用热图(heatmap)(不是地图上红一块绿一块那种热力图!),我之前的教程里用到的pheatmap函数就是这方面的好工具。
在之前,我们用命令is.na()的时候,其实已经看出缺失值的,但是目前我们数据缺省值很少,如果缺失值多怎么办?

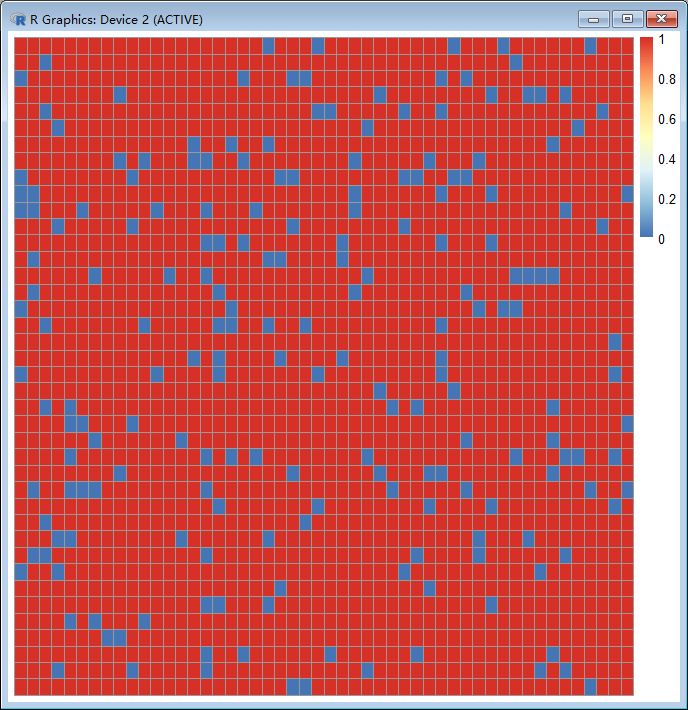
上图中的蓝点就是这批数据中的缺失值。
下面的话出自某网络博客。我觉得说的很对:
识别缺失数据的数目、分布和模式有两个目的:分析生成缺失数据的潜在机制,评价缺失数据对回答实质性问题的影响。我们需要弄清楚以下几个问题:
缺失数据的比例多大?
缺失数据是否集中在少数几个变量上,或者广泛存在?
缺失是随机产生的吗?
缺失数据间的相关性或与可观测数据间的相关性,是否可以表明产生缺失值的机制?
这些就是不那么容易解决的问题了,比如说,每一列缺失数据比例多大,可以很简单的用一行代码算出来:

至于第二个问题,缺失值是否存在某一些变量上,这样可以通过做barplot来看。

可以看出,大部分的列都有缺失值(那当然,我们是随机生成的缺失值。)
缺失值处理
一般来说,处理缺失值有两种办法:直接把数据删掉,或者用补足。删掉的意思就是,如果某一行出现了缺失值,无论这一行中缺失值有多少,直接将其删除,整行删除。补充的意思是,用附近的一些数据的值,计算一个估计值去填补这一个数。
直接删除的优缺点分别是:方便快捷,代码好写,但是有可能太多信息都会被遗漏掉。

补足(impute):的优缺点分别是:尽量保持了信息,但是如果一行数据10个,有9个是NA,那么补出来的数据也不会有多高的质量。
所以,缺失值处理是一个比较需要经验的问题,一般来说我的处理办法是,如果样本数据很多,比如列有上百个,那就先对列做缺失值比例计算,将缺失达到10%的样本直接删除。然后再剩下的数据中,按行做缺失值比例调查,将比例高达一定阈值(比如20%)的删掉,然后对剩下的数据做impute过程。
主要有以下方法,平均值法:

中值法:

特定值法:

异常值
异常值顾名思义就是偏离了“寻常值”的数据。但是多“异常”的值才能成为异常值,这就得看研究项目而定了。有些时候,异常值才是一个科研项目中应该去研究的问题。一般来说,有一个想对通用的检测异常值的标准,就是均值±三倍标准差。这个很好理解,你的均值是数据大部分“寻常值”的所在位置,标准差是其差异程度。那么3倍标准差很明显就说明一个数据严重地偏离了均值了。
下面我们用代码来写一下:

我们可以看到,在我随机生成了1000个随机数以后(正态分布,均值为0,标准差为1),只有2个数达到了异常值上届,也只有1个数达到了异常值的下届。
下面我们尝试把这些异常值画出来,其实代码特别简单:

该图的中文名叫做箱线图,其中上下的小圆点就是异常值的意思。最上边的横线是上边界,最下边是下边界,中间的箱体,上边缘是上四分位数,下边缘是下四分位数,中间最粗的横线是中位数(不是均值)。
个人觉得,有一个特别简单找出异常值的办法,就是使用boxplot函数

直接将boxplot存储成为一个变量tmp,tmp中的out子元素就是异常值。
对于异常值的处理也是花样繁多,有的人就直接把所有异常值设置成为NA,然后就回到了上边的缺失值部分。也有人保留他们,总之这方面算法很多,不一而足。异常值产生的原因很多,有很多时候,异常值其实不仅有意义,而且很重要:
比如,探查人流涌动,就是通过异常值来看那些地方突然人数激增?探查宇宙射线一类的科研,最关注的东西永远都是异常值。再大数定律横行其道的今天,几乎各种数据都是需要量化来达到规律总结的,这恰好令了“天鹅”一类事件越来越难以估计。所以对于异常值的处理和解读,其实正是数据分析人员的水平高下所在。